One of my vSphere 6.7 U3 environments I am managing was still using external Platform Services Controller (PSC) from times when it was the prescribed architecture. That is no longer the case so to simplify my management I wanted to get rid of the external PSC via so called Convergence to embedded PSC.
Unfortunately although there is a very nice UI to do this it never worked for me. And I did try multiple times. The error I always ended up was:
Failed to get RPMs.
The /var/log/vmware/converge/converge.log log did not show any error, but what was peculiar there was this entry referring to download of VCSA 6.5.0 files?!
These are obviously not correct for my 6.7 U3 VCSA appliance. This VMware Communities thread finally pushed me in the right direction.
Here are the steps how to resolve this:
Delete content of /root/vema directory on VCSA
Download correct VCSA ISO installation media corresponding to the version of your VC. In my case it was the full 4 GB VMware-VCSA-all-6.7.0-14836122.iso. The patch media VMware-vCenter-Server-Appliance-6.7.0.41000-14836122-patch-FP.iso cca 2 GB large did not work.
I was always bothered by slow performance of my lab installation of vSphere Web Client (version 5.5). Although my lab is small I have large number of plugins. I use the Windows installable version which is running together with vCenter, Inventory service, Update Manager and database server.
I noticed that the Java process was using over 1 GB of RAM. The fix was simple – add more memory to the VM and to Web Client Tomcat server:
Edit wrapper.conf file which is located in C:\Program Files\VMware\Infrastructure\vSphereWebClient\server\bin\service\conf.
and increase
wrapper.java.maxmemory=1024m
in the JVM Memory section. I increased the value to 3072m.
Private VLANs (PVLANs) are useful in multitenant environments where there is a need to provide access to single server for all customers while not allowing them to see each other and NAT or dedicated networks are not an option. Agent based backup with central backup server or VM monitoring are example of such use-cases.
There might be a constraint that does not allow the usage PVLAN. For example hardware that does not support it (Cisco UCS) or VXLAN logical network. The latter I used in one of my designs. There was a need for single backup network stretched over pods without L2 connectivity. VXLAN can overlay L3 fabric and thus create single network spanning the pods however VXLAN does not support PVLANs. If VMware NSX is used then distributed (in-kernel) firewall can be used instead. If vCloud Network and Security is providing the VXLAN networks then there is App Firewall (vShield App) which unfortunately provides significant performance and throughput hit as it is inspecting every packet/frame in user-space service VM. It also adds complexity to the solution.
Access Control Lists
As of vSphere 5.5 vSphere distributed switch (vDS) supports access control lists (ACL) at the portgroup level. The ACL configuration is available only via the vSphere Web Client in the vDS portgroup > Manage > Settings > Policies > Edit > Traffic filtering and marking section. The following configuration can be used to provide the similar behavior to private VLAN.
Rule 1: Allow VMs to Server
Action: Allow
Type: MAC
Protocol/Traffic type: any
VLAN ID: any
Source Address: any
Destination Address: MAC address of the promiscous server or router
Rule 2: Allow Server to VMs
Action: Allow
Type: MAC
Protocol/Traffic type: any
VLAN ID: any
Source Address: MAC address of the promiscous server or router
Destination Address: any
Rule 3: Allow ARP
Action: Allow
Type: MAC
Protocol/Traffic type: any
VLAN ID: any
Source Address: any
Destination Address: FF:FF:FF:FF:FF:FF
Rule 4: Drop all
Action: Drop
Type: MAC
Protocol/Traffic type: any
VLAN ID: any
Source Address: any
Destination Address: any
Screenshot of the final configuration:
Note: As with PVLANs there is still a security issue of the tenant misconfiguring VMs IP address and causing Denial-of-Service for another VM with the same IP address. There are ways to remediate it but out of scope of this article.
As I started experimenting with VMware Virtual SAN (VSAN) in my lab and am using consumer grade SSDs which are not on VSAN (beta) HCL I am worried about wear and tear of the memory cells who have limited write endurance.
I wondered if it is possible to access the SMART attributes of the disks and quick search showed that there is a KB article 2040405 written which still applies although not specific to vSphere 5.5.
From the ESXi console run esxcli storage core device listto get list of storage devices and then run esxcli storage core device smart get -d device to get the SMART data.
This is output of my Intel 520 drive.
Unfortunately another host with OCZ SSD does not display any data with an error:
Error getting Smart Parameters: CANNOT open device
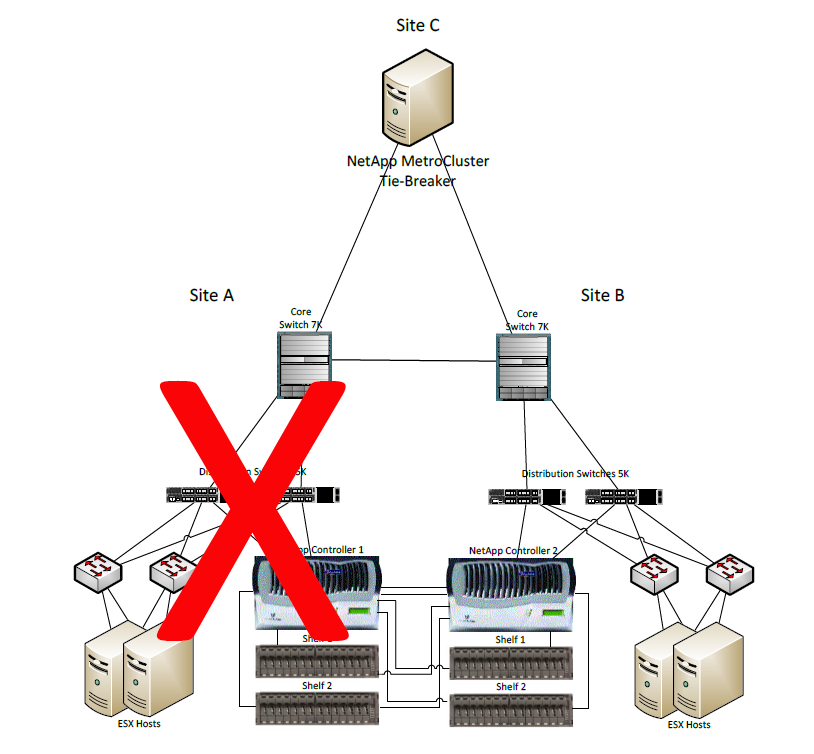
I am currently working of vSphere Metro Cluster Design (vMCS) with NetApp MetroCluster. vMSC is basically a stretched vSphere HA cluster between two sites with some kind of clustered storage solution. The idea is to leverage vSphere HA and vMotion to achieve high SLAs for planned or unplanned downtime.
While researching and simulating all the failure scenarios there is one particular that must include manual step. When there is complete site failure the surviving storage controller cannot distinguish between site failure or just a network partition (split brain). NetApp MetroCluster offers Tie-Breaker that needs to be deployed in a third datacenter and acts as a witness to help the surviving controller to decide what to do.
NetApp MetroCluster with Tie-Breaker and Full Site Failure
If the third datacenter is not available and Tie-Breaker cannot be implemented the storage controller takes no action and the storage administrator needs to do manual forced takeover of the storage resources on the surviving controller.
I was wondering how will vSphere infrastructure react to this and what steps the vSphere administrator will need to take to recover the failed workloads. VMware white paper VMware vSphere Metro Storage Cluster Case Study actually mentions this scenarion and says:
NOTE: vSphere HA will stop attempting to start a virtual machine after 30 minutes by default. If the storage team has not issued the takeover command within that time frame, the vSphere administrator must manually start virtual machines when the storage is available.
I was wondering how to streamline the manual vSphere administrator process of registering and starting the failed virtual machines but to my surprise in my test lab even if the storage failover took more than an hour, vSphere HA happily restarted all the failed VMs.
What is actually happening can be observed in the FDM logs of the HA master node. When the site fails following log message is repeating every minute:
[4CD9EB90 info ‘Placement’] [RR::CreatePlacementRequest] 6 total VM with some excluded: 0 VM disabled; 0 VM being placed; 6 VM waiting resources; 0 VM in time delay;
The HA master node tried to find suitable hosts to restart the six failed VMs from the failed site. As none of the available host had yet access to the storage needed by those VMs it was retrying every minute. Once I failed over the storage following messages immediately appeared:
[InventoryManagerImpl::ProcessVmCompatMatrixChange] Updating the existing compatibility matrix. … [VmOperationsManager::PerformPlacements] Sending a list of 6 VMs to the placement manager for placement.
The host to VM compatibility matrix was updated and immediately the placement manager found suitable hosts and HA restart process started.
This means you need not to worry about vSphere HA timeout. The timeout actually does not start ticking till the HA power on operation is attempted and then it takes 5 restart attempts in 0, 2 min, 6 min, 14 min and 30 minute time points.
P.S. Lee Dilworth and Duncan Epping actually had VMworld 2012 session about vMSC and this information is mentioned there.
Edit 8/8/2013
P.P.S. Duncan Epping blogged about HA and its dependence on compatibility matrix here.